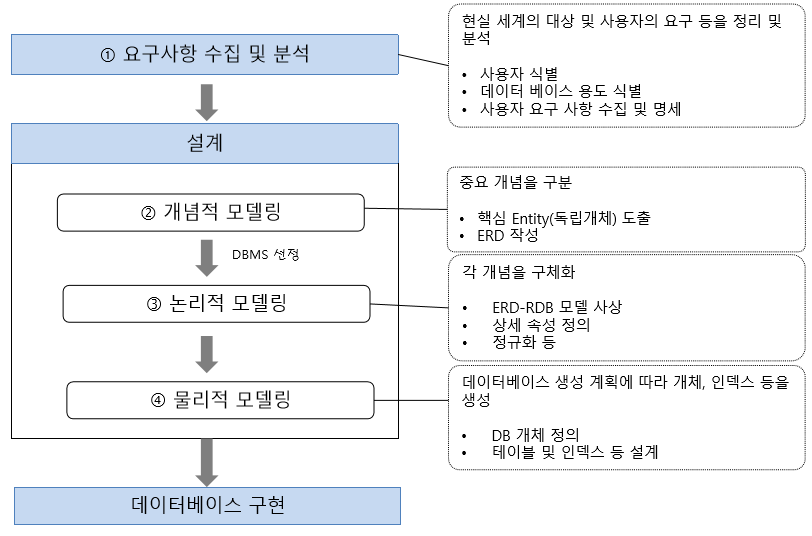
MongoDB 특징
- MongoDB는 Reliability(신뢰성), Scalability(확장성), Flexibility(유연성), Index Support(인덱스 지원) 4가지 특징을 가진 NoSQL Database 입니다.
Reliability(신뢰성)

- Primary와 Secondry로 구성된 Replica Set 구조로 고가용성을 지원합니다. 이를 통해 서버의 장애가 발생되어도 자체적으로 이를 회복하여 서비스가 정상적으로 운영되도록 할 수 있습니다.
Replica Set 동작
- MongoDB의 Replica Set은 기본적으로 1개의 Primary와 2개의 Secondary로 이루어져 있습니다.
- 쓰기 작업은 Primary가 담당하고, 읽기 작업은 Secondary가 담당합니다. 이를 통해 읽기/쓰기에 대한 부하를 분산할 수 있습니다.
- Primary는 쓰기 작업을 처리하여 데이터에 대한 변경 사항을 Secondary에 전달하여 동기화합니다.
- Primary 서버에 문제가 발생되어 사용할 수 없게 되었다면, 자동적으로 Secondary 서버를 Primary 서버로 설정하고 새로운 Secondary 서버를 셋팅하여 서버 장애에 대응합니다.
Scalability(확장성)

- 데이터와 트래픽이 증가함에 따라 데이터 샤딩을 통한 수평확장(scale-out)을 하여 부하 분산을 할 수 있습니다.
- Replica Set구조로 이루어진 각 Shard에 Shard Key를 기준으로 데이터를 분산하여 저장합니다.
- MongoDB는 RDBMS와 같이 정규화를 통한 테이블 분산을 거의 하지 않고, Document의 field에 배열 또는 Sub Document를 담음으로써 하나의 Document에 필요한 데이터를 모두 저장할 수 있습니다. 이를 통해 수평 확장에 대한 이점을 더욱 얻을 수 있습니다.
MongoDB의 밸런싱(Balancing)
- 몽고DB에 데이터가 증가하여 더 이상 하나의 Replica Set에 담을 수 없게 되거나 특정 샤드에 데이터가 몰리면 다른 샤드로 데이터를 이동 시켜, 전반적으로 모든 샤드가 균등하게 데이터가 저장될 수 있도록 합니다. 이러한 작업은 서비스 중단 없이 온라인 과정에서 진행됩니다. 그리고 이러한 동작을 밸런싱(Balancing)이라고 합니다.
Flexibility(유연성)

- 스키마 구조 변경 없이 여러 가지 형태의 데이터를 저장할 수 있기 때문에 서비스 요구 사항에 맞춰 다양한 형태의 데이터를 저장할 수 있습니다.
- JSON 형태로 데이터를 저장하고 읽기 때문에 개발자들 입장에서도 Object와 1:1로 매칭하여 사용할 수 있어 더욱 편리합니다.
- 하나의 Document에 배열 또는 Sub Document를 추가함으로써 RDBMS와 같이 join을 이용해 여러 테이블을 조회하는 상황을 줄일 수 있습니다.
Index Support(인덱스 지원)
- MongoDB Index에 대한 정리 글(https://vanilla-tech.tistory.com/entry/MongoDB-index-%EC%A2%85%EB%A5%98)
MongoDB의 Cluster 구조

- MongoDB의 Cluster 구조는 mongos, shard cluster, config server로 3개의 Component 구성됩니다.
- shard cluster에는 실제 데이터가 저장됩니다.
- config server에는 접근하고자 하는 데이터가 어떤 shard cluster에 저장되어 있는지 여부를 확인 수 있는 메타 데이터가 저장됩니다.
- app server는 mongos에만 연결하여 데이터를 요청합니다. mongos는 config server를 통해서 어떤 shard cluster에 데이터가 저장되었는지 확인하여 shard cluster에서 데이터를 가져와 app server에 응답합니다.
- 위와 같은 구조 덕분에 app server는 MongoDB의 Cluster 구조를 알 필요 없이 mongos에만 접근하여 원하는 데이터를 접근하고 조작할 수 있습니다. 덕분에 사용성 측면과 유지보수 측면에서의 이점이 있습니다.
BSON과 JSON
- MongoDB는 JSON 형태로 데이터를 저장하는 것처럼 보이지만, 실제로는 BSON(Binary JSON) 형태로 데이터를 저장합니다.
- JSON은 텍스트 기반으로 저장되기 때문에 구문 분석이 느리고, 공간 효율성이 떨어지고 데이터 타입 표현의 한계가 있습니다. 그렇기 때문에 사용자에게 보여질 때는 JSON으로 보여주고, 네트워크로 전송하고 저장할 때는 BSON으로 인코딩하여 처리합니다.
- BSON은 JSON보다 공간 효율성, 처리 속도, 다양한 데이터 타입 지원 부분에서 이점이 있습니다.
자료 출처 : https://tv.kakao.com/v/414072595
'데이터 베이스 > NoSQL' 카테고리의 다른 글
| MongoDB index 종류 (0) | 2023.03.22 |
|---|---|
| NoSQL이란? (0) | 2023.01.14 |
| mongoDB 기본 개념 및 용어 설명 (0) | 2023.01.13 |
| MongoDB transaction 사용법 (0) | 2023.01.08 |