RUDP( Reliable UDP )란 신뢰할 수 있는 UDP로서 UDP를 랩핑하여 안전한 송.수신을 구현한 프로토콜을 말합니다.
RUDP를 사용하는 여러가지 이유
TCP보다 빠르고 안정적인 송.수신 프로토콜을 구현하기 위해 사용합니다.
TCP는 IP와 포트를 기준으로 연결을 수립하지만 RUDP는 프로그래머가 어떻게 구현하느냐에 따라서 연결 기준을 변경할 수 있습니다. 이러한 장점은 이동할 때마다 중계기가 변경되어 IP가 바뀌는 모바일 환경에서 매우 이점이 있습니다. 예를들어서 대중교통을 이용하면서 TCP 통신을 하는 모바일 게임을 즐기고 있다면 중계기가 바뀔 때마다 연결이 끊길 것입니다.
RUDP 구현에 필요한 스펙
TCP의 3-way-handshake와 같이 연결할 PC간의 연결 정보를 교환하여 세션을 수립하는 작업이 필요합니다.
UDP는 송신하려는 데이터의 크기를 그대로 네트워크 계층으로 전달하기 때문에 네트워크 계층에서 MTU 사이즈 초과로 분할되는 것을 방지하기 위해서 송신하려는 데이터의 크기를 조절하여 사용해야 합니다.
TCP가 오류 제어, 흐름 제어, 혼잡 제어를 통해서 안전한 송.수신을 구현한 것처럼 RUDP에도 이와 같은 스펙이 구현되어야 합니다.
TCP의 네이글 알고리즘이 활성화 되어있는 상태에서 데이터를 송신할 때 바로 송신하지 않고 최대 MSS( TCP 세그먼트 페이로드의 최대 크기를 의미하며 보통 1460byte입니다. )크기 만큼 데이터를 버퍼링하여 송신합니다.
네이글 알고리즘을 사용하는 이유
송신할 데이터를 버퍼링하지 않고 Send 버퍼에 데이터가 적재될 때마다 송신한다면 패킷 마다 TCP 헤더, IP 헤더, 이더넷 헤더가 붙기 때문에 네트워크 트래픽량이 증가됩니다. 그렇기 때문에 송신할 데이터는 최대한 버퍼링하여 한 번에 송신하는 것으로 네트워크 트래픽을 줄일 수 있습니다.
네이글 알고리즘이 활성화 되었을 때 데이터 전송 조건
송신하려는 데이터가 MSS 크기만큼 버퍼링 되었을 때 송신합니다.
버퍼링하는 도중에 일정 시간이 지났다면 MSS 크기만큼 버피링 되어 있지 않더라도 송신합니다.
데이터를 버퍼링 하는 도중에 상대방으로부터 ACK가 왔다면 MSS 크기만큼 버퍼링 되어 있지 않더라도 데이터를 송신합니다.
네이글 알고리즘의 단점
송신하려는 데이터를 MSS만큼 버퍼링하고 송신하기 때문에 매우 빠른 응답성을 요구하는 격투 게임같은 경우에서는 사용자가 딜레이를 느낄 수 있습니다.
네이글 알고리즘을 비활성화하는 방법
setsockopt 함수를 통해 TCP_NODELAY 옵션을 주면 네이글 알고리즘을 비활성화 할 수 있습니다.
TCP는 흐름 제어, 오류 제어, 혼잡 제어 이 세 가지 제어 기능으로 안정적인 1:1 송.수신을 구현합니다. 이러한 기능들 덕분에 TCP를 사용할 경우 상위 레이어에만 개발에 집중할 수 있습니다.
흐름 제어
흐름 제어는 상대방의 window size를 고려하여 송신 데이터의 크기를 조절하고 응답에 상관없이 window size만큼 데이터를 연속적으로 송신하는 기능을 담당합니다.
Stop and wait
데이터를 송신하면 상대방이 데이터를 잘 수신 받았는지 여부를 확인하기 위해 ACK 응답을 기다립니다. ACK 응답의 Acknowledge Number를 통해서 수신 여부 및 정말로 보낸 데이터 만큼 잘 수신 받았는지를 확인할 수 있습니다.
Sliding window
sliding window는 TCP가 3-way-hasdshake 과정에서 알아냈던 상대방의 window size만큼 수신 응답을 기다리지 않고 데이터를 연속적으로 보내며 수신자 측은 지금까지 수신받았던 데이터 크기와 Sequence Number를 기반으로 Acknowledge Number를 셋팅하여 한 번에 응답합니다. 이러한 기능 덕분에 TCP의 패킷 당 송.수신 확인 응답으로 인한 지연을 줄일 수 있습니다.
오류 제어
TCP는 일정시간 수신자에게 응답이 없거나 송신 데이터가 잘못되어 NACK(Negative Ack)로 응답이 올 경우 자동으로 재전송하는 ARQ(Automatic Repeat Request) 기법을 사용합니다. 그리고 TCP는 Checksum과 Sequence Number, Acknowledge Number를 이용해서 송.수신 데이터의 오류를 검출하며 Go Back N, Selective Repeat을 혼합한 형태로 오류 제어를 합니다.(Stop and Wait 전송 속도가 매우 느리고 효율이 낮아서 사용되지 않습니다.)
Stop and Wait
데이터를 송신하고 수신자로부터 일정시간 동안 ACK 응답이 없어 timeout이 되거나 NACK가 올 경우 전송했던 데이터를 재전송합니다.
Go Back N ( GBN )
Go Back N 방식은 위와 같이 sliding window를 이용해 연속적으로 데이터를 보내다가 timeout으로 데이터가 유실되었음을 인지하거나 수신자로부터 NACK 응답이 왔을 경우 문제가 발생된 데이터부터 다시 재전송하는 방식을 말합니다. 구현은 간단하지만 잘못된 데이터부터 모두 다시 보내야 한다는 단점이 있습니다.
Selective Repeat( SR )
Selective Repeat은 모든 응답에 대해서 ACK를 보내고 누락되거나 잘못된 패킷에 대해서만 NACK를 통해 재전송 요청을 합니다. 중간에 잘못되거나 누락된 패킷이 재전송되어 수신할 경우 기존에 받았던 패킷들과 순서에 맞게 재조합을 해야하기 때문에 추가적인 작업과 버퍼가 필요합니다. 또한 모든 패킷에 대한 응답이 필요하기 때문에 네트워크 트래픽이 증가될 수 있습니다.
데이터를 연속적으로 송신하다가 중간의 데이터가 유실되어 동일한 ACK가 지속적으로 올 경우 timeout을 기다리지 않고 데이터가 유실되었다고 판단하여 재전송합니다.
혼잡 제어
통신하는 네트워크 내의 트래픽이 과도하게 증가하여 송.수신이 원활하게 이루어지지 않는 상태를 혼잡이라고 합니다. TCP가 패킷 유실률 그리고 응답 속도를 종합하여 혼잡도를 판단합니다. 그리고 혼잡 제어는 네트워크의 혼잡한 현상을 방지하고 제거하기 위해 사용되는 기능입니다.
Awnd는 실제로 수신자가 한 번에 데이터를 수신받을 수 있는 최대 버퍼 크기를 의미합니다.
Cwnd는 TCP가 네트워크 혼잡도에 따라서 실제로 수신자에게 한 번에 송신할 수 있는 데이터 크기를 의미하며, 최대 크기는 Awnd입니다.
Slow Start
TCP는 처음 연결직후 Cwnd의 사이즈를 1로 하고 임계 지점을 Awnd의 1/2로 합니다. 수신자로부터 ACK 응답을 받을 때마다 Cwnd 사이즈를 2베씩 증가시켜가며 Cwnd가 임계 지점에 도달했다면 ACK 응답을 받을 때마다 1씩 증가시켜 Awnd 크기 만큼 증가시킵니다.
timeout이 발생되었다면 네트워크가 혼잡하다고 판단하여 Cwnd를 1로 하고, 임계 지점의 크기를 반으로 줄인 후 다시 Slow Start 방식으로 Cwnd를 증가시킵니다.
Fast Retransmit( 빠른 재전송 ) & Fast Recovery( 빠른 회복 )
sliding window를 통해서 패킷을 송신하는 도중에 중간 패킷이 유실되어 수신자가 유실전 패킷에 대한 ACK를 3번 연속으로 보내게 될 경우 timeout을 기다리지 않고 유실된 패킷을 재전송합니다. 이러한 방식을 Fast Restransmit이라 하며, 이를 통해 TCP는 네트워크의 혼잡함을 인지하여 Cwnd를 1이 아닌 1/2로 줄이며 해당 지점을 임계 지점으로 설정합니다. 이후 ACK를 받을 때마다 1씩 최대 Awnd만큼 증가시키며 이를 Fast Recovery 라고 합니다.
3-way-handshake는 TCP로 데이터를 송.수신하기 전에 1:1 연결하려는 PC간에 연결 정보를 교환함으로써 연결을 수립하는 과정을 말합니다.
3-way-handshake 과정
클라이언트는 connect() 함수를 호출하여 listen 상태의 서버에게 응답 패킷의 SYN 플래그를 활성화하고 임의의 Sequence Number를 담고 연결 정보와 같이 SYN 패킷을 송신합니다. 이 때 클라이언트의 연결 상태는 SYN-SENT 상태가 됩니다.
SYN 패킷을 받은 서버는 수신 받은 패킷의 Sequence Number를 확인하고 응답하는 패킷에 SYN, ACK 플래그를 활성화하고 클라이언트의 Sequence Number에 1을 더하여 Acknowledgment Number를 셋팅합니다. 그리고 패킷에 임의의 Sequence Number와 연결정보와 같이 SYN/ACK 패킷을 송신합니다. 이 때 서버의 연결 상태는 SYN-RECEVED 상태가 됩니다.
서버의 응답을 받은 클라이언트는 ESTABLISHED 상태가 되어 연결 완료 상태가 되며, 서버에게 SYN-ACK 패킷에 담긴 Sequence Number에 1을 더하여 응답 패킷의 Acknowledgment Number를 셋팅하고 ACK 플래그를 활성화 후 응답을 합니다.
클라이언트의 응답을 받은 서버는 ESTABLISHED 상태가 되어 TCP 최종 연결이 완료됩니다.
3-way-handshake가 필요한 이유
상호 연결정보를 교환할 때 얻은 Sequence Number, Acknowledgment Number, Window Size를 통해서 패킷이 몇 번째 패킷인지 그리고 패킷을 어디까지 수신 받았는지를 확인할 수 있습니다. 내가 송신한 패킷에 대한 ACK를 확인하여 상대방이 내가 송신한 패킷을 어디까지 수신 받았는지 확인하여 재전송 및 다음 패킷을 송신합니다.
Window Size는 Sliding Window에 사용됩니다. Sliding Window는 응답이 오지 않아도 상대방의 Window Size 만큼 데이터를 송신하고 상대방은 수신 받은 여러개의 패킷에 대해서 하나의 ACK로 응답합니다. 이로 인해 ACK를 기다림으로써 발생되는 딜레이 및 네트워크 트래픽량을 줄일 수 있습니다.
4-way-handshake
4-way-handshake는 1:1 연결된 TCP 세션간의 연결을 끊기 위한 과정을 말합니다.
4-way-handshake 과정
연결을 종료하려는 쪽이 close() 함수를 호출하여 FIN 플래그가 활성화된 패킷을 상대방에게 송신하며 이때 연결 상태는 FIN_WAIT_1 상태가 됩니다.
FIN 패킷을 수신받은 쪽은 FIN 패킷의 Sequence Number에 1을 더하여 Acknowledgment Number에 셋팅하여 ACK 패킷으로 응답하며 이때 연결 상태는 CLOSE_WAIT 상태가 됩니다.
FIN 패킷에 대한 ACK를 받은쪽은 FIN_WAIT_2 연결 상태가 되며, 상대방이 FIN 패킷을 송신하기만을 기다립니다.
CLOSE_WAIT 상태에서 close() 함수를 호출하면 상대방에게 FIN 패킷을 송신하며 연결 상태는 LAST_ACK 상태가 됩니다.
FIN_WAIT_2 상태에서 FIN 패킷을 받은쪽은 FIN 패킷의 Sequence Number에 1을 더하여 Acknowledgment Number에 셋팅하여 ACK 패킷으로 상대방에게 응답 후 연결 상태는 TIME_WAIT 상태가 됩니다.
LAST_ACK 상태에서 FIN에 대한 응답은 받으면 연결 상태가 CLOSED 상태가 되어 TCP 연결이 종료됩니다.
4-way-handshake가 필요한 이유
4-way-handshake 연결 종료 절차를 통해 상호 세션을 정리하는 과정을 수행할 수 있습니다. 하지만, FIN 패킷을 처음으로 보내는 PC는 TIME_WAIT이 남아 해당 IP에 대한 PORT를 한동안 사용할 수 없게 됩니다.
이러한 TIME_WAIT이 남는 이유는 연결 종료 후에 동일한 포트가 바로 재사용되어 새로운 세션이 수립되었을 때 이전에 연결되었었던 상대방이 송신한 패킷이 뒤늦게 수신되어 잘못 처리될 수 있는 확률이 있기 때문에 TIME_WAIT을 통해서 해당 포트가 재사용되지 않도록 합니다.
하지만, TIME_WAIT이 없다 하더라도 위와 같은 불상사가 발생할 확률은 매우 희박합니다. 왜냐하면 TCP는 안전한 송.수신을 보장하기 때문에 Sequence Number와 Acknowledgment Number가 일치해야 처리할 수 있기 때문입니다.
동일한 네트워크 망에 있는 해커가 GARP( gratuitous ARP )를 이용해 라우터에게 공격 대상의 IP주소와 자신의 MAC주소를 맵핑하여 송신하고, 공격자에게는 게이트 웨이 IP주소와 자신의 MAC주소를 맵핑하여 송신합니다. 그러면 위 이미지에서와 같이 공격 대상자는 외부망에 메시지를 송신할 때마다 해커의 PC를 거치게 되고 모든 외부에서 해당 공격 대상자의 PC로 들어오는 메시지에 대해서 해커의 PC를 거치게 됩니다.
위와 같은 공격이 가능한 이유는 ARP는 자체적으로 IP주소와 MAC주소를 검증하는 기능이 없기 때문입니다.
GARP( gratuitous ARP )
GARP( gratuitous ARP )는 ARP 테이블 갱신 및 IP 주소 충돌 감지를 하기위해 사용되는 프로토콜입니다.
미리 DB 서버와 Connection들을 만들어 놓고 필요할 때마다 Connection Pool에서 이미 연결되어 있는 Connection을 가져오고 이용해 반납하는 방식을 DBCP( DB Connection Pool )이라고 합니다. 이 덕분에 TCP의 Connect을 맺고 끊는 추가적인 작업을 서버가 가동될 때 한 번에 처리하기 때문에 네트워크 트래픽과 성능의 이점이 있습니다.
DBCP를 사용하기 위한 DB 서버 설정 몇가지
DB 서버의 max_connections
Connection Pool을 설정할 때 DB 서버의 max_connections의 개수를 설정해야 합니다. 이때 고려해야 할 부분은 여러 대의 서버에서 Connection Pool을 사용할 것을 고려해서 설정해야 합니다.
DB 서버의 wait_timeout
wait_timeout은 connection이 inactive 할 때 다시 요청이 오기까지 얼마의 시간을 기다린 뒤에 close할 것인지를 결정할 때 사용합니다.
vertical partitioning은 column을 기준으로 partitioning을 하기 때문에 테이블의 스키마가 변경되지만, horizontal partitioning은 row를 기준으로 partitioning을 하기 때문에 테이블의 스키마는 유지됩니다.
horizontal partitioning이 필요한 이유
테이블에 튜플이 점점 추가됨에 따라서 인덱스의 크기도 커지기 때문에 테이블에 읽기/쓰기/수정/삭제가 있을 때마다 인덱스에서 처리되는 시간도 조금씩 늘어납니다.
horizontal partitioning 종류
hash-based horizontal partitioning은 특정 attribute를 해쉬하여 나온 값을 기준으로 partitioning을 하는 것을 말합니다.
range-based horizontal partitioning은 특정 attribute의 범위를 정하여 partitioning을 하는 것을 말합니다.
hash-based horizontal partitioning
특정 attribute를 hash하여 hash에 나온 값을 기준으로 테이블을 나누어 저장하는 방식을 말합니다. hash에 사용된 attribute를 partition key라고 합니다.
hash-based horizontal partitioning 주의점
partition key는 가장 많이 사용될 패턴에 따라 선택해야 테이블을 나눈 이점을 최대한 얻을 수 있습니다.
한 번 partition을 나눈 테이블에 partition을 추가하는 것은 굉장히 어렵습니다. 이미 저장된 데이터의 partition key를 기준으로 재해쉬하여 다시 partition하여 저장해야하기 때문입니다.
sharding
sharding은 horizontal partitioning으로 나누어진 table들을 각각의 DB서버에 저장하는 방식을 말합니다.
sharding에서 partition key를 shard key라고 부릅니다. 그리고 각 partition을 shard라고 부릅니다.
sharding이 필요한 이유
horizontal partitioning은 결국 하나의 DB서버에서 나누어진 partition을 관리하기 때문에 각 partition에 대한 요청도 하나의 DB서버에 몰려 부하가 집중됩니다. 그렇기 때문에 DB 서버의 부담을 줄이기 위해서 sharding을 통해 각 shard을 독립된 DB서버에 저장하여 각 shard에 대한 요청을 분산하여 DB서버의 부하를 줄일 수 있습니다.
replication
DB를 복제해서 여러 대의 DB 서버에 저장하는 방식을 말합니다.
기존 DB를 master/primary/leader라고 부르며 복사된 DB를 slave/secondary/replica라고 부릅니다.
secondary는 primary와 데이터가 동일한 상태에서 primary에 요청되어 변경된 데이터들을 계속해서 확인하여 sync를 맞춥니다.
secondary는 여러 대가 있을 수 있습니다.
replication의 High availability(고가용성) 이점
서비스중에 primary DB서버에 문제가 생겼다면 secondary중에 하나가 primary를 대체하여 서비스가 정상적으로 유지될 수 있도록 할 수 있습니다. 이처럼 자동적으로 장애를 극복하여 서비스가 유지되도록 하는 것을 failover라고 합니다.
replication의 읽기/쓰기 분산 이점
대부분의 서비스는 write보다는 read 트래픽이 훨씬 많습니다. write는 동기화를 확실히 맞출 필요가 있지만 대부분의 서비스에서 read는 정확한 동기화까지는 필요가 없기 때문에 read를 secondary로 처리할 수 있도록 하여 부하 분산을 할 수 있습니다.
RDBMS에서 index의 종류는 크게 Clustered 와 Non-Clustered 로 나뉩니다.
Clustered Index란?
Clustered는 군집화 라는 뜻을 가집니다. 즉, Clustered Index는 군집화된 인덱스로서 데이터와 인덱스를 합쳐놓은 인덱스를 Clustered Index라고 합니다.
Clustered Index는 사전에서 가나다 순으로 찾기 좋게 정렬되어 있고, 책의 모서리에 ㄱ, ㄴ ,ㄷ 표시를 확인하여 접근하는 방식과 유사합니다.
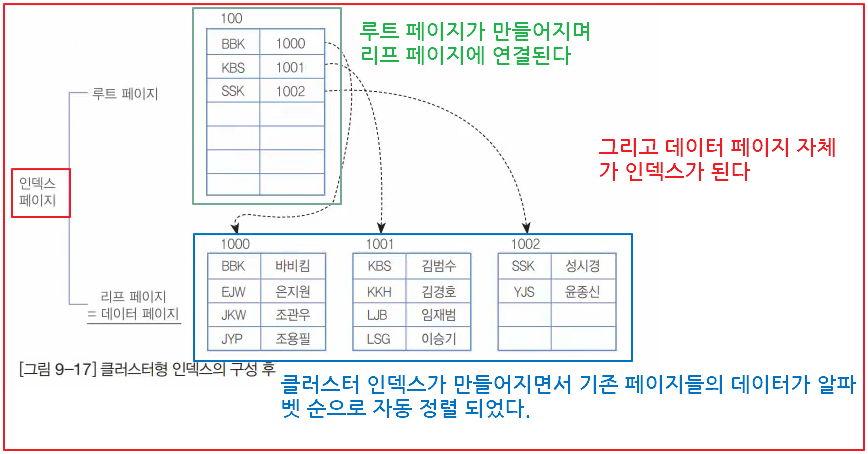
Clustered Index 작동 방식과 특징
Clustered Index를 만들면 위 그림에서와 같이 루트 페이제에 각 Index 값과 리프 페이지의 위치 정보에 해당하는 첫 번째 데이터를 맵핑시켜 저장합니다.
데이터 페이지는 Clustered Index를 기준으로 항시 자동 정렬됩니다.
데이터 페이지를 리프 페이지로 사용합니다.
한 테이블에 한 개씩만 만들 수 있습니다.
MySQL에서는 Primary Key가 있다면 Clustered Index로 지정되며, Primary Key가 없다면 unique하면서 not null인 컬럼을 Clustered Index로 하며 이것도 없다면 보이지 않는 컬럼을 만들어 Clustered Index로 지정합니다.
Clustered Index 장점
데이터 자체가 Clustered Index를 기준으로 정렬되어 있으며, 리프 페이지가 곧 접근하고자 하는 데이터이기 때문에 인덱스를 위한 추가적인 저장 공간을 사용할 필요가 없습니다.
Non-Clustered Index보다 Index를 통한 검색 속도가 빠릅니다.
Clustered Index 단점
데이터 페이지는 Clustered Index를 기준으로 정렬되기 때문에 기존에 많은 데이터가 추가된 테이블에 Clustered Index를 지정하면 DB에 많은 부하가 발생됩니다.
Non-Clustered Index보다 Index를 통한 검색 속도가 빠르지만, 입력/수정/삭제는 상대적으로 더 느립니다.
Non-Clustered Index란?
Non-Clustered Index는 보조 인덱스로서 <목차> 또는 <찾아보기>를 통해서 페이지 넘버를 확인하고 접근하는 방식과 유사합니다.
Non-Clustered Index 작동 방식
Non-Clustered Index 역시 루트 페이지가 만들어집니다. 하지만, Clustered Index 처럼 리프 페이지가 데이터 페이지인 것과는 달리 리프 페이지에 index 값과 데이터 페이지에서 몇 번째 위치에 Index인지에 대한 대한 정보를 맵핑하여 저장합니다.
Non-Clustered Index는 index와 위치 정보를 맵핑한 테이블 데이터가 필요하기 때문에 추가적인 저장 공간이 필요합니다.
데이터 페이지는 정렬하지 않고 리프 페이지에 있는 Index를 기준으로 정렬합니다.
데이터 페이지에는 직접적인 영향을 주지 않기 때문에 Clustered Index 달리 여러개 생성이 가능합니다.
Non-Clustered Index 장점
Clustered Index보다 Index를 통한 검색 속도가 느리지만, 입력/수정/삭제는 상대적으로 더 빠릅니다.
입력/수정/삭제 시 데이터 페이지가 아닌 리프 페이지만을 정렬 시키기 때문에 Clustered Index보다 DB에 주는 부하가 적습니다.
Non-Clustered Index 단점
리프 페이지에는 Index에 대한 값과 맵핑된 데이터 페이지의 위치 정보를 맵핑한 저장 공간이기 때문에 Clustered Index 보다 필요한 저장 공간이 더 필요합니다
리프 페이지에서 데이터 페이지로 접근하기 때문에 Clustered Index 보다 검색 속도가 상대적으로 느립니다.
select * from customer where first_name = 'Minsoo';
first_name에 index가 걸려있지 않다면 테이블 전체를 scan하여 first_name의 값이 'Minsoo'인 튜플을 찾습니다. 이를 full scan이라고 하며 이때 시간 복잡도는 O(N)입니다.
first_name에 index가 걸려있다면 full scan보다 더 빨리 찾을 수 있습니다. 만약, B-tree 기반의 index라면 이때 시간 복잡도는 O(logN)입니다.
index의 이점을 얻을 수 있는 쿼리문들 몇가지
select * from customer where first_name = 'Minsoo';
delete from logs where log_datetime < '2022-0101';
update employee set salary = salary * 1.5 where dept_id = 1001;
select * from employee as E join department as D on e.dept_id = d.id;
위 쿼리문들의 조건 부분에 index를 주었을 때 성능의 이점을 얻을 수 있는 쿼리문입니다.
사용중인 player 테이블에 index 걸기
id
name
team_id
backnumber
-- 중복을 허용하는 index 생성
-- create index (index 이름) on 테이블명 (attribute 이름);
create index player_name_idx on player (name);
-- 중복을 허용하지 않는 index
-- backnumber는 중복되기 때문에 temm_id와 같이 묶어서 index 처리
create unique index team_id_backnumber_idx on plyaer (team_id, backnumber);
player 테이블을 생성하면서 index 걸기
create table player(
id int primary key,
name varchar(20) not null,
team_id int,
backnumber int,
index player_name_idx (name), -- name은 동명이인이 있기 떄문에 그냥 index 그리고 index이름은 생략 가능
unique index team_id_backnumber_id (team_id, backnumber)
);
show index from player;
team_id, backnumber와 같이 두 개 이상의 컬럼을 이용해 index를 거는 경우를 multicolumn index 또는 composite index 라고 합니다.
primary key에는 RDBMS가 자동으로 unique index로 생성합니다.
show index player; 는 player 테이블에 있는 index 정보를 가져올 수 있습니다.
B-tree 기반의 index의 동작 방식
위 그림에서의 왼쪽은 a attribute의 index를 걸었을 때 오름 차순으로 생성되는 a와 a값을 가진 튜플에 대한 맵핑 테이블입니다.
위와 같은 index 정보를 기반으로 a에 대한 조건으로 튜플을 찾을 때 바이너리 서치를 통해 접근합니다.
where a = 7 and b = 95;에 대한 조건으로 튜플을 찾는다면 a는 index 정보를 기반으로 바이너리 서치를 하지만 b는 a를 기준으로 찾은 튜플을 대상으로 full scan을 합니다.
B-tree 기반의 multicolumn index의 동작 방식
위 그림에서 왼쪽은 a, b를 묶어서 index를 걸었을 때 a에 대한 오름차순 후에 b에 대한 오름 참순으로 생성된 index입니다. 즉, 왼쪽 column을 기준으로 오른쪽으로 오름 차순으로 index를 생성하기 때문에 multicolumn index를 만들 때 컬럼의 순서가 중요합니다.
where a = 7 and b = 95;에 대한 조건으로 튜플을 찾는다면 a = 7에 대한 조건을 바이너리 서치로 먼저 찾은 후 b = 95에 대한 조건을 바이너리 서치로 찾아 접근합니다. 그렇기 때문에 where a = 7 and b = 95;을 조건으로 찾는 쿼리문이 많다면 a, b를 index로 설정하는 것이 좋은 선택일 수 있습니다.
만약, 위와 같이 index가 걸려있는 상태에서 where b = 95; 조건으로 튜플을 검색하더라도 위의 index를 온전히 활용하여 성능을 뽑아낼 수는 없습니다. 그렇기 때문에 where b = 95;를 조건으로 하는 쿼리문이 많다면 b에 대한 index를 생성하는 것이 좋을 수 있습니다.
만약, 위와 같이 index가 걸려있는 상태에서 where a = 7;를 조건으로 튜플을 검색하면 a에 대한 값을 기준으로 index가 생성되어 정렬되어 있기 때문에 index를 이용한 성능을 보장받을 수 있습니다.
EXPLAIN
index가 위 그림에서 나온것 처럼 걸려있다면 backnumber를 조건으로 튜플을 검색할 때 어떤 index를 이용해 검색하는지를 확인하고 싶다면 EXPLAIN을 통해 확인이 가능합니다. possible_keys는 사용 가능한 index에 대한 이름을 의미하며, key는 사용된 index에 대한 이름을 의미합니다.
use index & force index & ignore index
위와 같이 조건문에 대한 index를 어떤 것으로 선택할지는 RDBMS의 optimizer가 알아서 선택하지만, 간혹 의도하지 않은 index를 선택하여 성능이 좋지 못한 경우가 있습니다. 그럴 경우 위 그림에서와 같이 use index를 이용해서 어떤 index를 사용할지 명시할 수 있습니다.
use index 문법은 권장해 달라고 요청하는 문법이지만, 강력하게 어떤 index를 사용하라고 요청할 때에는 force index를 사용합니다.
만약 특정 index를 사용하지 않겠다면 ignore index(index name) 문법을 사용하면 됩니다.
index를 주의해서 사용해야 하는 이유
index를 생성할 때마다 위와 같이 index에 대한 테이블이 생성되기 때문에 추가적인 저장 공간이 필요합니다.
index가 걸린 attribute에 write를 할 때마다 B-tree를 다시 조정해야 하는 추가작업이 필요합니다.
만약 index(team_id, backnumber)가 걸려있다면 team_id에 대한 추가적인 index는 불필요 합니다.
Covering index
위 그림에서와 같이 team_id를 이용해서 team_id, backnumber에 대한 데이터를 가져올 때 필요한 데이터가 index에 모두 있다면은 player 테이블에 접근하지 않고 index에 있는 데이터만을 가지고 select 문을 수행합니다. 이를 통해 테이블에 접근해야 하는 추가적인 작업이 없기 때문에 성능이 훨씬 좋으며, 이를 Covering index라고 하며 의도해서 Covering index를 만드는 경우도 있습니다.
B-tree index와 Hash index의 차이
hash table을 기반으로 index를 구현합니다.
시간 복잡도는 O(1)입니다.
데이터가 추가됨에 따라서 rehashing이 일어날 수 있습니다.
index를 조건으로 하여 쿼리문을 수행할 때 equality 비교만 가능하며 >, =>, <, <= 와 같은 range 비교는 불가능합니다.
B-tree에서 (a, b)와 같이 multicolumn index를 지정하면 a만을 이용해 index를 활용할 수 있지만, hash 기반의 index는 무조건 (a, b)로 조건을 걸었을 때만 index를 활용할 수 있습니다.
Full scan이 좋은 경우
table에 데이터가 몇 백건 정도만 있는 경우 Full scan을 통한 검색이 나을 수 있습니다.
조회하려는 데이터가 테이블의 상당 부분을 차지하면 Full scan이 더 나을 수 있으며 이 또한 optimizer가 판단합니다.
테이블을 설계할 때 데이터 중복과 일관성 그리고 insertion, update, deletion anomaly를 최소화하기 위해 테이블을 분해하는 과정을 말합니다.
Normal forms란?
정규화되기 위해 준수해야 하는 몇 가지 rule들이 있는데 이 각각의 rule을 normal form(NF)라고 부릅니다.
정규화를 알아보기 전의 간단한 용어 정리
prime attribute는 임의의 key에 속하는 attribute를 의미합니다.
non-prime attribute는 어떠한 key에도 속하지 않는 attribute를 의미합니다.
DB 정규화 과정
1NF -> 2NF -> 3NF -> BCNF -> 4NF -> 5NF -> 6NF
DB 정규화는 1NF부터 순차적으로 진행하며 앞 단계를 만족해야 다음 단계로 진행할 수 있습니다.
최소 정규화
1NF ~ BCNF까지는 FD와 key만으로 정의되는 normal form입니다.
보통 3NF까지 도달하면 정규화됐다고 말합니다. 실무에서도 3NF 혹은 BCNF까지만 진행하며 많이해도 4NF까지만 진행합니다.
정규화 예시
정규화할 employee_account 테이블
bank_name
account_num
account_id
class
ratio
empl_id
empl_name
card_id
임직원의 월급 계좌를 관리하는 테이블입니다.
월급 계좌는 국민은행이나 우리은행 중 하나입니다.
한 임직원이 하나 이상의 월급 계좌를 등록하고 각 계좌의 입금될 월급 비율(ratio)을 조정할 수 있습니다.
계좌마다 등급(class)가 있습니다. ( 국민 : STAR -> PRESTIGE -> LOYAL, 우리 : BRONZE -> SILVER -> GOLD )
한 계좌는 하나 이상의 현금 카드와 연동될 수 있다.
primary key는 account_id입니다.
1NF
bank_name
account_num
account_id
class
ratio
empl_id
empl_name
card_id
Kookmin
010-1221-1732
a21
LOYAL
1
e2
Messi
c201 c202
1NF는 attribute의 value는 반드시 나눠질 수 없는 원자 값이어야 합니다.
card_id의 value를 보게된다면 나눠질 수 있는 값이기 때문에 1NF를 위반하고 있습니다.
2NF 과정
bank_name
account_num
account_id
class
ratio
empl_id
empl_name
card_id
Kookmin
010-1221-1732
a21
LOYAL
1
e2
Messi
c201
Kookmin
010-1221-1732
a21
LOYAL
1
e2
Messi
c202
위 테이블은 1NF를 만족합니다.
모든 non-prime attribute는 모든 key에 fully functionally dependent해야 합니다. {account_id, card_id} key를 보았을 때 account_id만을 가지고 {class, ratio, empl_id, empl_name}의 non-prime attribute를 식별할 수 있습니다. 즉, {class, ratio, empl_id, empl_name}가 부분 함수적 종속된 상태입니다. 이와 같이 잘못된 테이블 설계로 인해서 card_id가 추가되었을 때 { class, raito, empl_id, empl_name }의 중복 데이터가 발생됩니다.
X -> Y, Y -> Z 관계로 인해 X -> Z가 성립되는 관계를 transitive FD라고 합니다.( Y와 Z는 어떤 key에 대해서도 부분 집합이 아니여야 합니다. )
3NF는 모든 non-prime attribute는 어떤 key에 transitively dependent 하면 안됩니다. 즉, non-prime attribute들 간의 FD가 성립되면 안 됩니다. 즉, {bank_name, account_num}은 후보키 이기 때문에 {account_id} -> {class} -> {bank_name}는 이행 함수족 종속에 해당되지 않습니다.
BCNF
bank_name
account_num
account_id
class
raito
empl_id
Woori
010-9231-1121
a11
BRONZE
0.1
e1
Woori
102-992-180125
a12
SILVER
0.2
e1
Woori
010-9231-1121
a13
LOYAL
0.7
e1
Kookmin
010-1221-1732
a21
LOYAL
1
e2
empl_id
empl_name
e1
Sony
e2
Messi
account_id
card_id
a21
c201
a21
c202
위 테이블들은 3NF를 만족합니다.
class는 bank 마다 다 다른 계급을 가지기 때문에 {class} -> {bank_name} FD 관계를 가집니다.
BCNF는 모든 유효한 non-trivial FD의 X -> Y는 X가 반드시 후보 키 여야 합니다.
BCNF까지 만족한 테이블
account_num
account_id
class
raito
empl_id
010-9231-1121
a11
BRONZE
0.1
e1
102-992-180125
a12
SILVER
0.2
e1
010-9231-1121
a13
LOYAL
0.7
e1
010-1221-1732
a21
LOYAL
1
e2
bank_name
class
Woori
BRONZE
Woori
SILVER
Woori
LOYAL
Kookmin
LOYAL
empl_id
empl_name
e1
Sony
e2
Messi
account_id
card_id
a21
c201
a21
c202
2NF 주의점
empl_id
empl_name
birth_date
position
salary
company
1
...
...
...
...
ez.
2
...
...
...
...
ez.
3
...
...
...
...
ez.
company attribute의 값은 고정됨을 가정하겠습니다.
위 테이블의 FD는 {empl_id} -> {empl_name, birth_date, position, salary, company}와 {} -> {company} 가 있습니다. 그리고 {}는 {empl_id}에 부분집합이며 company는 {empl_id}에 부분 함수적 종속관계이기 때문에 2NF를 만족하지 못합니다.
위와 같은 예외 상황이 발생될 수 있기 때문에 2NF는 key가 composite key( 두 개 이상으로 이루어진 key )가 없다면 자동적으로 2NF를 만족한다? 라고 할 수는 없습니다.
denormalization 이란?
empl_id
empl_name
birth_date
position
salary
1
...
...
...
...
2
...
...
...
...
3
...
...
...
...
company
ez.
위 테이블은 2NF를 만족시키기 위해서 {empl_id} primary key의 부분 함수족 종속인 company attribute를 분리하여 {}->{company}를 제거하고 company를 위한 새로운 테이블을 구성하였습니다. 위와 같은 정규화는 어떻게 보면 과할 수 있습니다. 그리고 경우에 따라서 테이블을 너무 과도하게 분리하게 될 경우 너무 많은 join으로 인한 성능 저하 그리고 관리적인 측면에서 어려움이 있기 때문에 적정 수준을 잘 조절하며 정규화를 해야합니다.