트랜잭션( Transaction )이란?
- 트랜잭션(Transaction)은 하나 이상의 SQL 문을 나눠질 수 없는 논리적인 작업 단위로 묶어 처리하는 기능을 말합니다. 그렇기 때문에 transaction의 SQL문들 중에 일부만 성공해서 DB에 반영되는 일은 일어나지 않습니다.
트랜잭션 사용방법
J가 H에게 20만원을 이체하는 트랜잭션
-- 트랜잭션 시작을 의미
start transaction;
update account set money - 200000 where id = 'J';
update account set money + 200000 where id = 'H';
-- commit을 통해 지금까지 작업한 내용을 DB에 영구적으로 저장 후 트랜잭션 종료
commit;
- start transaction 을 실행하면 autocommit은 off가 됩니다.
- commit 또는 rollback을 실행하면 autocommit은 원래 상태로 돌아갑니다.
J가 H에게 30만원을 이체도중 롤백
-- 트랜잭션 시작을 의미
start transaction;
update account set money - 300000 where id = 'J';
-- 지금까지 작업들을 모두 취소하고 transaction 이전 상태로 되돌린 후 트랜잭션을 종료
rollback;
autocommit 이란?
-- autocommit 활성화 확인하는 SQL
select @@autocommit;
-- autocommit 비활성화
set autocommit = 0;
- 각각의 SQL문에 대해서 자동으로 transaction 처리를 해주는 기능입니다. SQL문이 성공적으로 실행되면 commit 실패할 경우 rollback을 자동으로 진행합니다. ( MySQL에서는 autocommit이 default로 활성화되어 있습니다. )
트랜잭션의 ACID( Atomicity, Consistency, Isolation, Durability )란?
- ACID는 Atomicity, Consistency, Isolation, Durability의 앞 글자를 딴 약자이며, 각각의 단어는 트랜잭션이 가져야 하는 속성을 의미합니다.
Atomicity( 원자성 )
- 트랜잭션의 내부 SQL문들을 원자적으로 묶어 모두 성공하거나 모두 실패하는 결과만 나오는 속성을 의미합니다.
Consistency( 일관성 )
- 트랜잭션 수행 도중 테이블에 등록된 constraints, trigger 등을 통해 DB에 정의된 rules을 트랜잭션이 위반했다면 rollback해야 합니다. 그 외에도 application 관점에서 트랜잭션이 consistent하게 동작하는지 개발자가 확인하여 commit해야 합니다.
- 예를들어 50만원밖에 없는 H가 J에게 100만원을 입금하는 것을 트랜잭션으로 처리한다면 H는 100만원도 없기 때문에 Consistency를 유지할 수 없어 트랜잭션 도중 실패하여 rollback을 해야합니다.
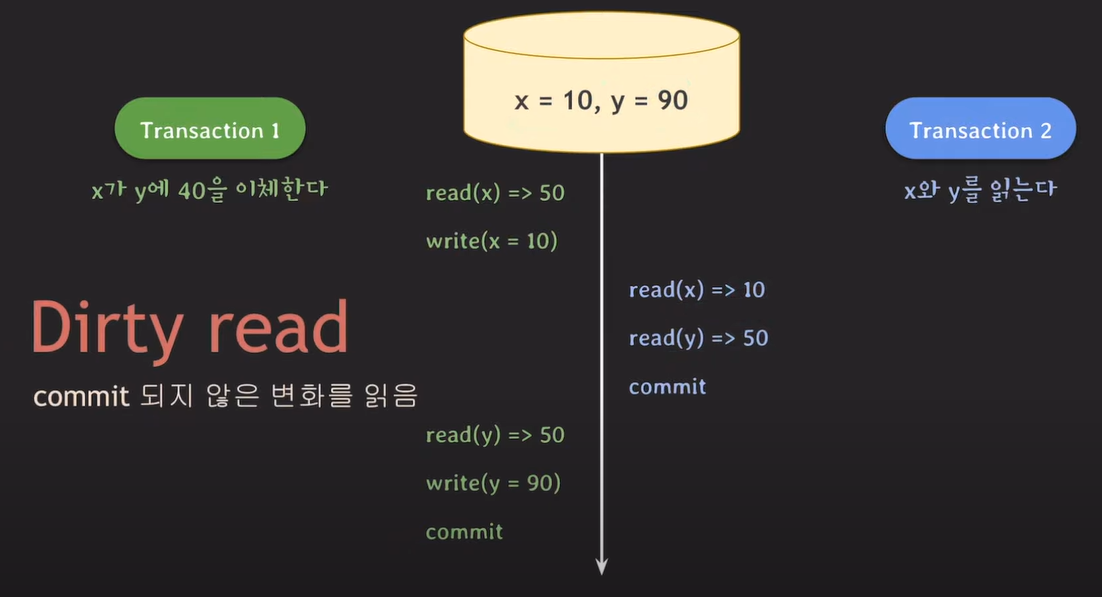
Isolation( 독립성 )
- 트랜잭션이 수행될 때 다른 트랜잭션에 의해 영향을 받지 않아야 하는 속성을 의미합니다.
- 트랜잭션의 Isolation이 너무 엄격하면 DB의 퍼포먼스가 떨어질 수 있기 때문에 DBMS 종류에 따라서 isolation level을 제공합니다. isolation level이 낮으면 엄격한 격리성이 낮아져 트랜잭션의 동시성이 높아집니다. 하지만, 다른 트랜잭션에 의해서 예상치 못한 결과가 나올 수도 있기 때문에 신경써서 사용해야 합니다.
Durability( 영속성 )
- commit된 트랜잭션은 DB에 영구적으로 반영되는 속성을 의미합니다.